Production infrastructure for AI agents.Monitor what runs. Improve what fails.Compound learnings. All in one platform.
Building AI agents is easier than ever. Trusting one in production isn't.
Prompt changes, model swaps, and new tools reach production as silent regressions - caught by your customers, not your dashboards.
When you do find a regression, the context is scattered - traces in one tool, evals in another, fixes in a third. None of them feed back into the agent.
So every release starts from zero. Learnings don't compound. Neither does your AI investment.
Bento is the closed-loop platform for teams
to ship self-improving agentic systems.
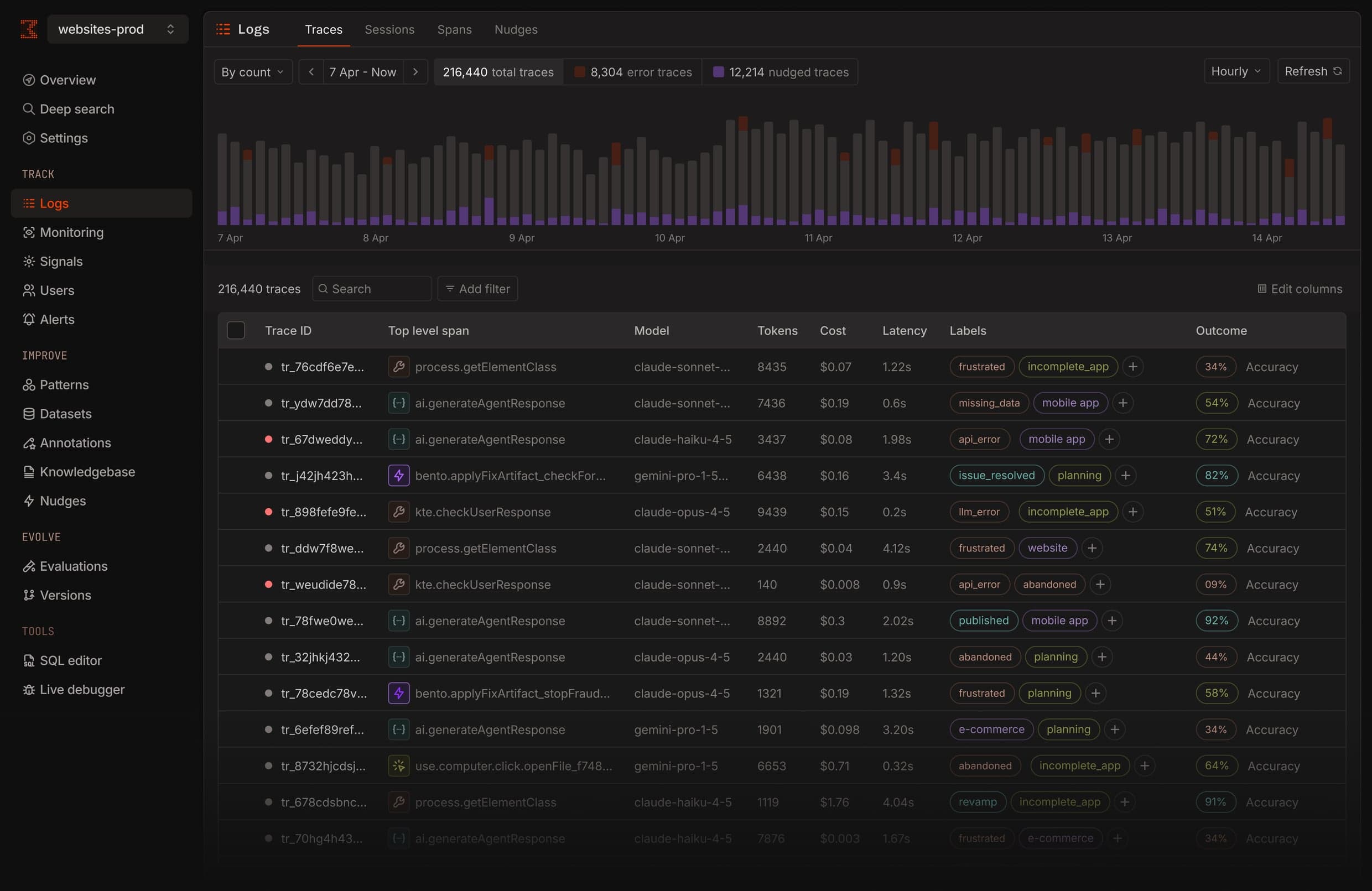
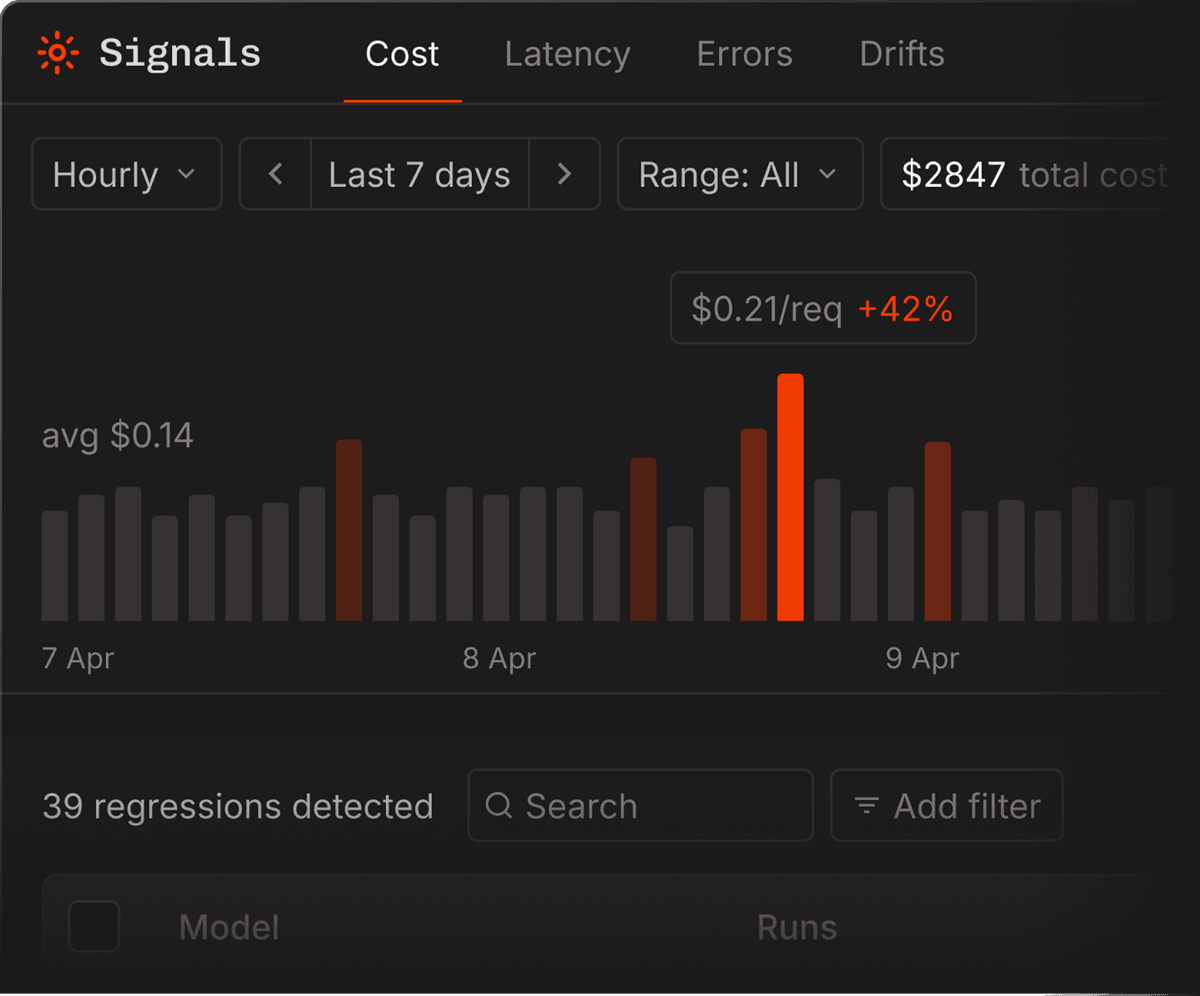
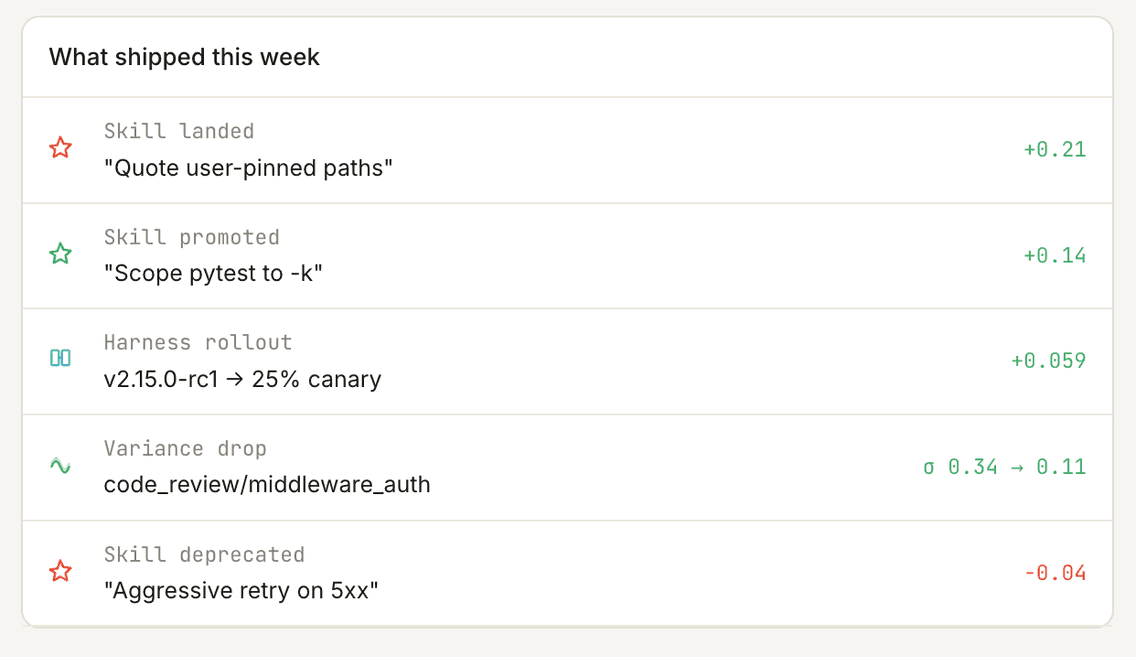
Regression signals
Describe any failure mode in plain English — Bento trains a signal on your own traces, fires it in real time, and backfills your entire history to show how long it's been happening.
Every span, captured
OpenTelemetry-native traces from every framework you run. Jump into the span tree, or follow a signal badge straight to the call that broke.

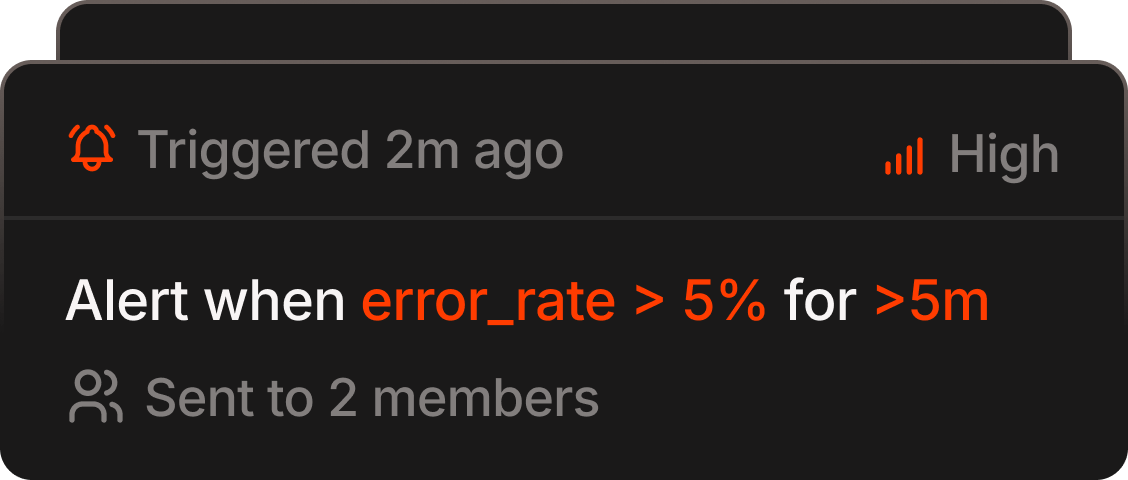
Alerts
Write alerts in English. Bento groups fires into incidents and judges each one real or benign — so you only wake up for real drift.
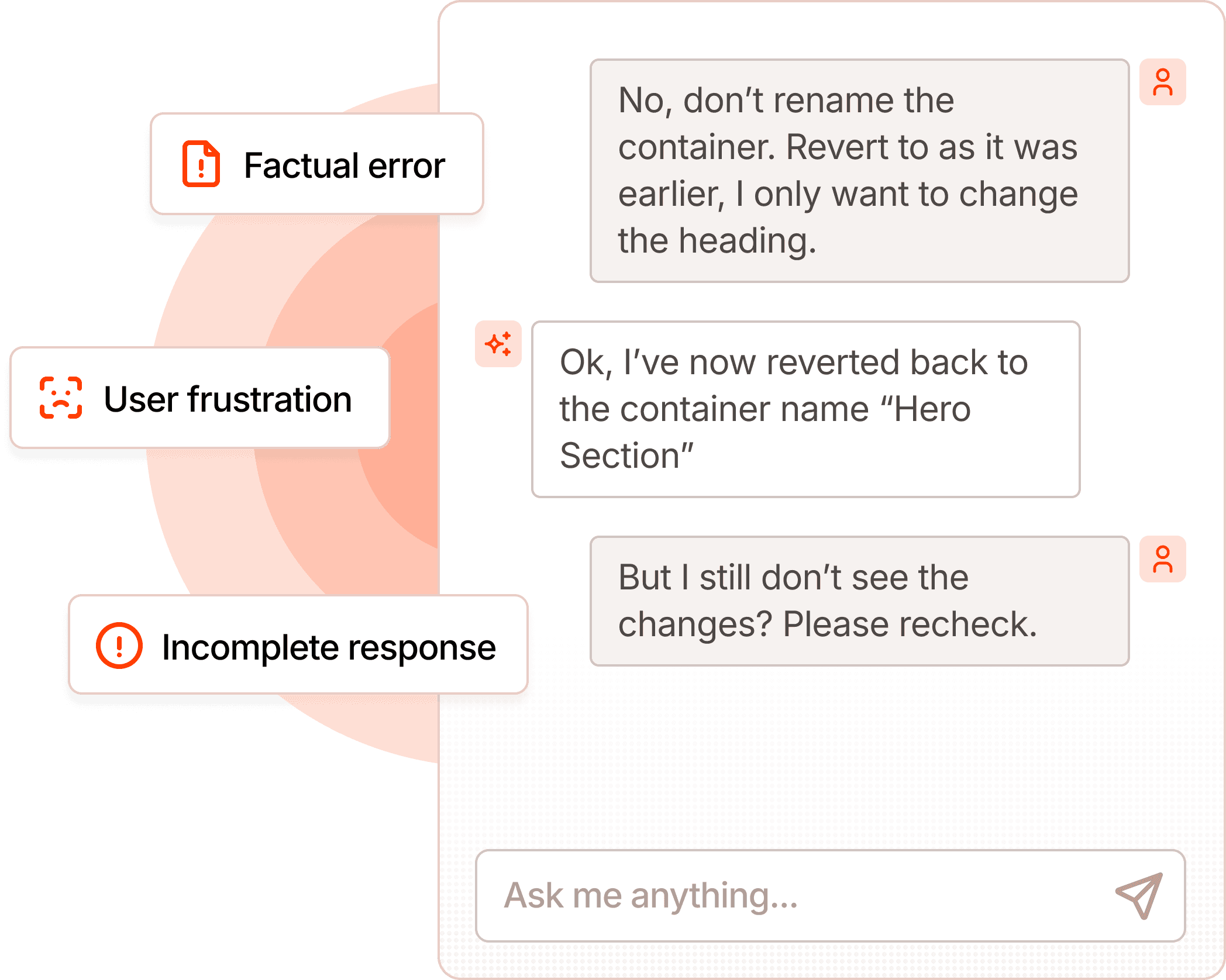
Behavioral drift
See when your agent starts behaving differently — Bento pinpoints exactly what shifted.
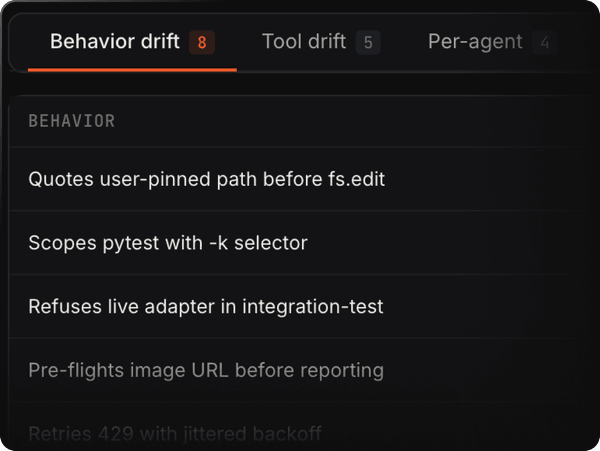
Improve your agents with each production run.
- 01
Artifacts
Reusable, trigger-based fixes: skills, subagents, and tools that graduate from candidate to promote as they prove themselves in production.
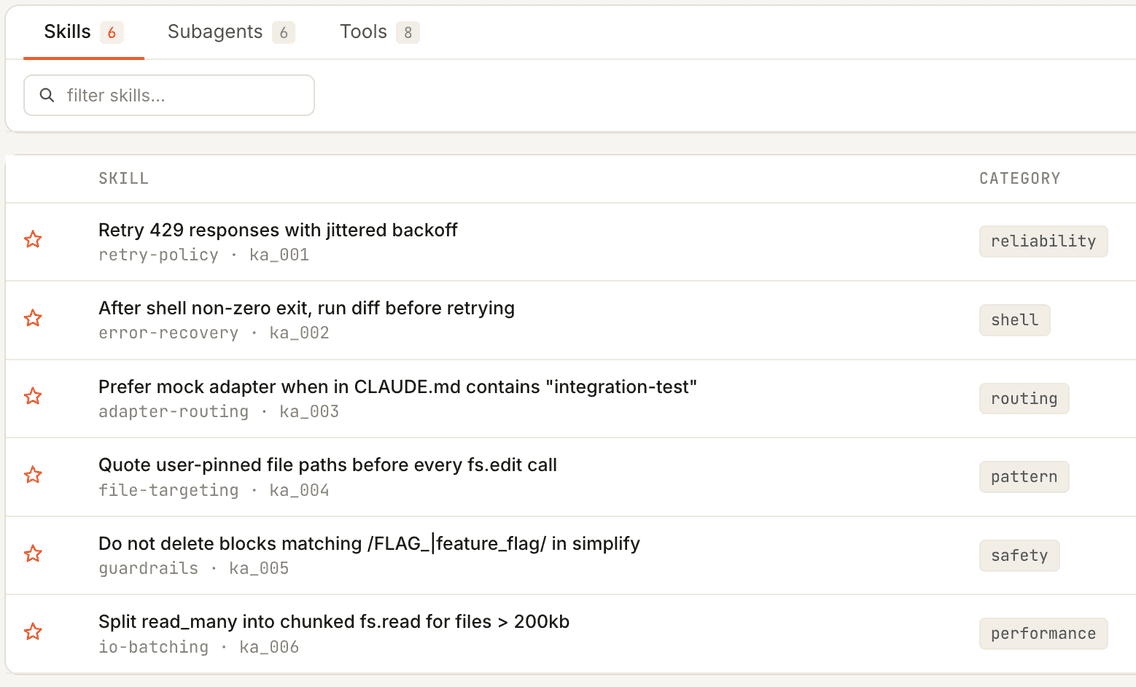
- 02
The Book
A living memory of what your agent has learned — every failure pattern, fix, and outcome, in plain language.
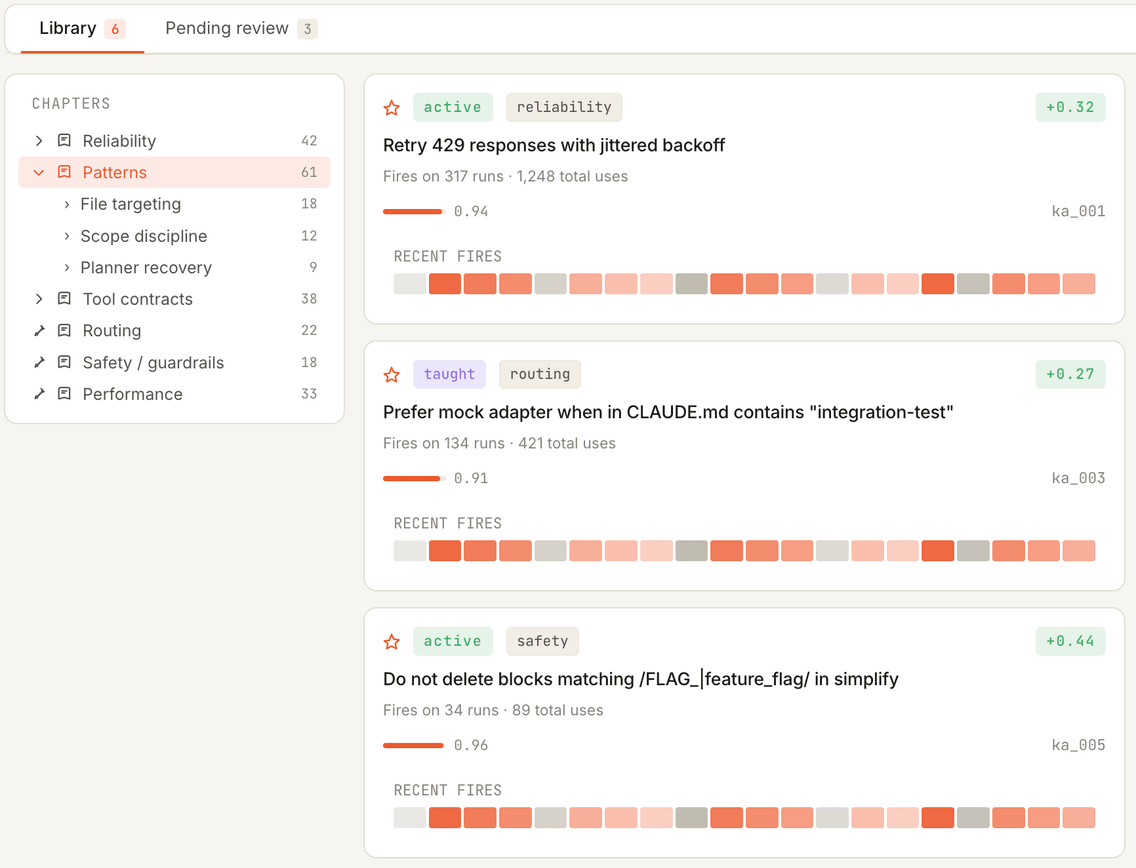
- 03
Evaluations
Every release scored against your production history — offline, in CI, and on live traffic, catching regressions before users do.
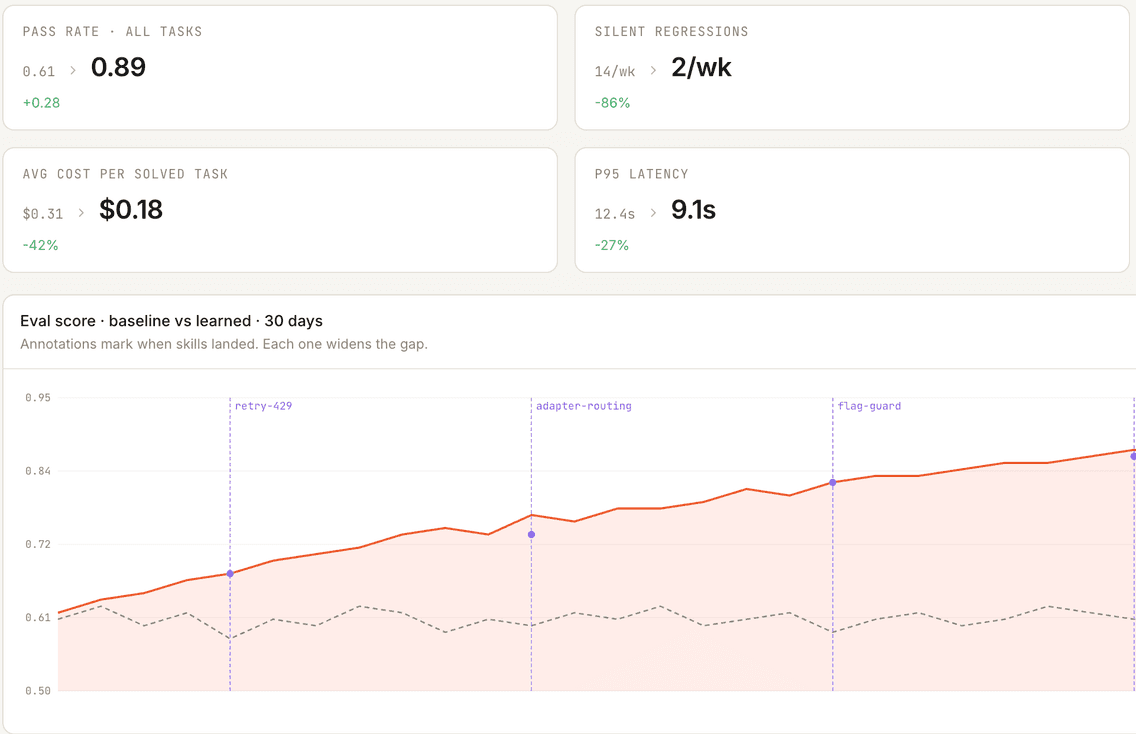
- 04
Versions
Every prompt, skill, and model change is versioned, diffable, and reversible — trace any regression back to the change that caused it.
Research and field notes on running AI agents at enterprise scale.
 RESEARCH
RESEARCH2.6× higher scores on ARC-AGI-3 with a self-learning layer: same agent, same budget
We validated a self-learning engine on ARC-AGI-3. Same agent, same tools, same budget — 2.6× the score, 34% cheaper per successful outcome, three first-ever solves.
8 min read
 PERSPECTIVE
PERSPECTIVEWhy you can't vibe-code your way to a better production agent
Vibe-coding finds a fix for the trajectories you pasted in — not the 999 you didn't. Improving a production agent takes infrastructure, not a chat session.
6 min read