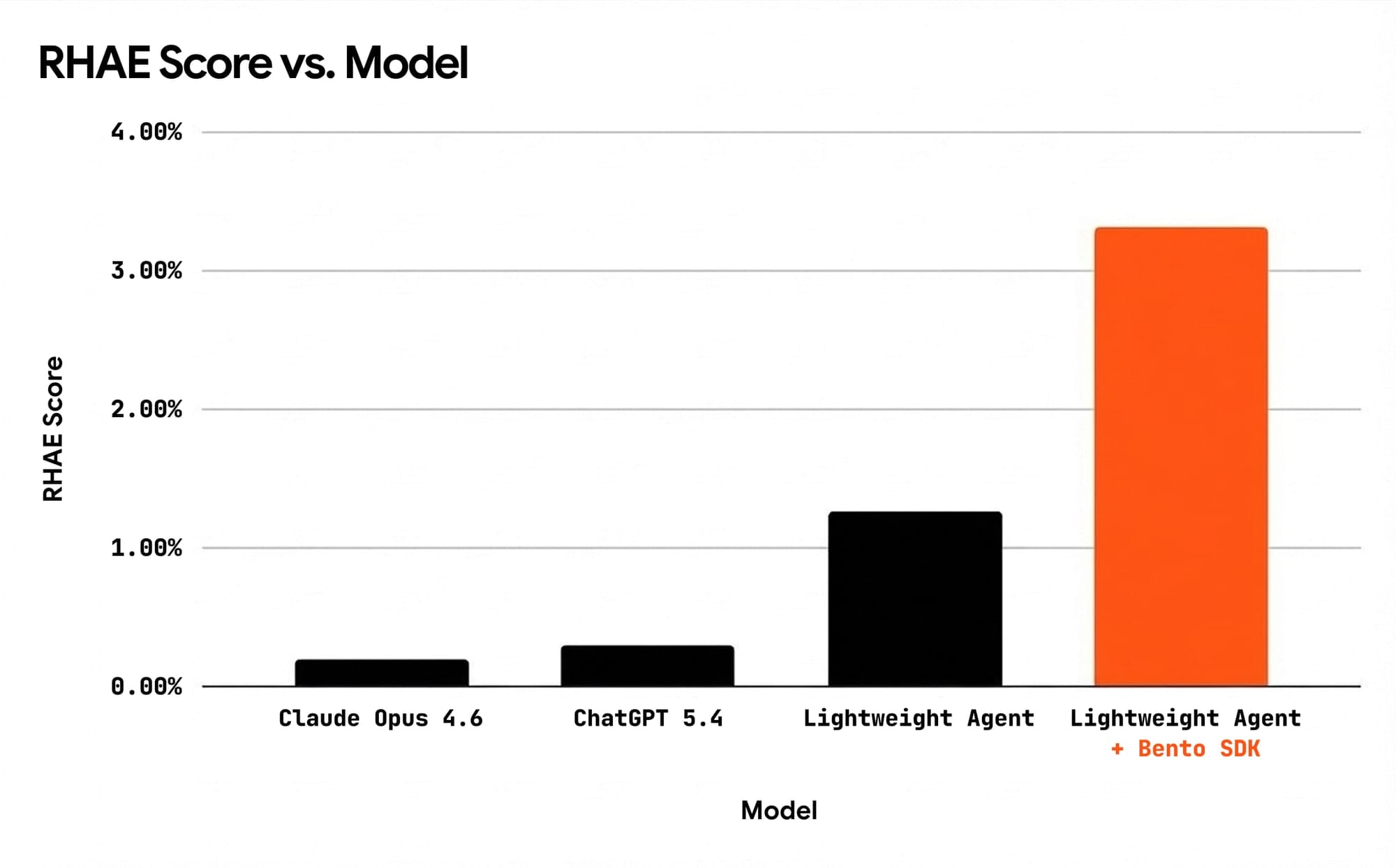
2.6× higher scores on ARC-AGI-3 with a self-learning layer: same agent, same budget
We validated a self-learning engine on ARC-AGI-3, the hardest interactive benchmark for AI agents. Frontier models score 0.2–0.3% out of the box. Our baseline agent scored 1.27%. With self-learning enabled, keeping the same agent, same tools and same budget, it scored 3.32%.
The result
| Metric | Agent only | Agent + self-learning | Delta |
|---|---|---|---|
| Avg RHAE (official score) | 1.27% | 3.32% | +2.6× |
| Total levels solved | 16 | 22 | +6 |
| Head-to-head wins | 3 games | 11 games | 9 ties |
| First-ever solves | — | 3 games | — |
Three games the agent could never crack, across dozens of prior runs, multiple model configurations, and every prompt strategy we tried, were solved for the first time with self-learning active. Cost per level solved dropped 34%.
The LLM did not get smarter. The agent just stopped wasting its intelligence rediscovering the same answers and patterns twice.
This post walks through what we built, how the experiment worked, and what we learned.
How production AI agents improve today
There is a standard playbook. Most teams know it because they have lived it.
When a new model drops, be it Claude, ChatGPT or Gemini, performance jumps. Teams plan their entire improvement cycles around these release schedules. When model gains plateau, teams turn to prompt engineering: system prompts, few-shot examples, and better context construction deliver real gains.
When specific failures surface, engineers step in and investigate. They dig into traces in Langfuse or LangSmith, find the root cause, and ship fixes.
Each step works and delivers real improvement. Each also shares a ceiling.
Every improvement the agent made lives only in the past run. The agent itself retains nothing: the edge cases it solved before, failures it already encountered, and patterns it uncovered do not carry forward. None of it is available when the agent starts its next run.
Run 1 and Run 100 perform the same, minus stochastic variance. Every run starts from zero. Every time the agent rediscovers a solution it already found three runs ago, it is wasted tokens spent on nothing.
We saw this across millions of traces at Emergent, where we were early hires and held SWE-Bench #1. An integration the agent would nail once, then burn its entire budget rediscovering the same API sequence from scratch. The knowledge existed. It had nowhere to live.
The industry has been optimising for long-run performance. The compounding question of whether each run makes the next one better has started to pop up. And we are here to take that up.
We tried fine-tuning and RL — here is how it compares with our SDK:
| Fine-tuning / RL | Bento's recursive learning | |
|---|---|---|
| Cost | $100K+ per run | $500–1K in API calls |
| Time | Weeks | Hours |
| Output | Opaque weights | Readable files you can edit |
| New model drops | Start over | Knowledge auto-transfers |
| Infrastructure | GPU clusters | Just API calls |
| Team required | ML engineers | Any engineer |
| Auditability | None | Every artifact inspectable |
Agents that learn from experience
Think about how a good engineer improves their work. They do not start from scratch on every ticket. Instead they accumulate a mental library of patterns, recurring issue types, and the specific questions that surface root causes faster, over hundreds of cases. This accumulated but invisible experience shapes every future interaction.
Production agents can work the same way. The signals are already there in every trace, every failed run, every edge case an agent investigated. What is missing is a system that captures what those runs teach and makes it available for the next one. The real delta is in putting down the right nudge at the right time.
Observability tools like Langfuse, LangSmith, and Braintrust are excellent at telling you what happened. They do not make that data useful for what comes next. The feedback loop between runs is the missing layer. Capability and knowledge are fundamentally different problems. Most teams have been solving for the former; knowledge is the one that actually compounds.
Turning that knowledge into a compounding asset requires a dedicated layer.
How the self-learning engine works
BentoLabs plugs into your existing agent harness via an SDK. It also integrates with your existing OTel-based observability stack. There is no rearchitecting and no new infrastructure required.
Three things happen continuously:
After each run, the engine reviews the agent's path, records what worked, what failed, and why, and turns useful lessons into reusable knowledge. It saves successful text, code, workflows, and patterns so future runs can avoid the same problems and build on what already proved effective.
Before every run, the most relevant knowledge is retrieved from the accumulated knowledge base and injected into the agent's context. Retrieval matches against the task description and what the agent is about to solve, pulling only what is relevant. The agent starts with the accumulated understanding of prior runs.
During the run,a lightweight oversight layer monitors the agent's trajectory and steps in when the agent is stuck. This combines pattern detection with targeted interventions grounded in what has actually worked before.
The knowledge base self-curates over time. After each run, we evaluate how injected learnings affected the outcome. Learnings that consistently lead to success get promoted. Learnings that cause confusion or inconsistent results get demoted and archived. The system gets cleaner over time, not just bigger.
The experiment
We wanted to validate on something genuinely hard. Something that actually tests whether an agent can learn. We needed results that could not be explained away by tuning a harness to a specific domain's patterns.
Why ARC-AGI-3
ARC-AGI-3 is a benchmark of 25 puzzle games on a 64×64 grid. Each game contains multiple levels of increasing difficulty. The agent must discover hidden rules through experimentation, build mental models, and solve levels efficiently.
Scoring uses RHAE (Relative Human Action Efficiency). For each level, it measures how many actions the agent took compared to how many a human needed. If a human solves a level in 10 actions and the agent takes 50, the agent scores 20% on that level. A score of 100% means the agent matched human efficiency. Later levels carry more weight. Brute-forcing early levels while failing later ones produces a low overall score. The benchmark rewards genuine learning across a game, not getting lucky on level one.
Frontier models like Opus and Gemini score 0.2–0.3% out of the box. The benchmark demands iterative problem-solving where accumulated knowledge should matter. Mechanics transfer across levels. Similar puzzle types recur across games. Failure patterns repeat.
Setup
We used the same agent, same model, same system prompt, same tools, same action budget. The only variable was whether self-learning was active.
| Controlled variable | Value |
|---|---|
| Agent model | Claude Opus 4.6 |
| System prompt | Identical across both conditions |
| Available tools | 13 |
| Action budget | Dynamic, 5× human baseline per game |
| Game environment | ARC-AGI-3 API, identical versions |
The harness
Built on the Google ADK, the setup uses 11 tools for game interaction (actions, grid observation, snapshots), Python code execution (persistent REPL), and reasoning (hypothesis tracking, scratchpad). The system prompt instructs a three-phase loop:
- Probe the grid to map action effects.
- Build a Python simulator to predict game rules.
- Plan optimal sequences.
Since scoring is quadratic, the system is specifically designed to optimise for minimum actions.
All 25 public games. All baselines ran to natural completion. Single-shot runs with no cherry-picking.
Disclaimer. This is an internal benchmark study, not a competition submission. We use ARC-AGI-3 as a controlled environment to measure the impact of self-learning, not to compete on the leaderboard.
Results
Full 25-game evaluation
| Metric | Agent only | Agent + self-learning | Delta |
|---|---|---|---|
| Avg RHAE (official score) | 1.27% | 3.32% | +2.6× |
| Total levels solved | 16 | 22 | +6 |
| Head-to-head wins | 3 games | 11 games | 9 ties |
| First-ever solves | — | 3 games | — |
34% cheaper per successful outcome.
lp85: circuit rotation puzzle (a first-ever solve)
This one is worth walking through.
Both agents, baseline and self-learning, discovered that clicking position (5, 32) changed 293 cells. This was the key mechanic. Both then drifted into clicking dead zones, exploring other positions that did nothing useful.
The baseline agent tried 21 additional clicks at random positions and never returned to (5, 32). It exhausted its budget.
The self-learning agent also drifted. But the oversight layer delivered a single nudge: Your earlier click returned Changed: 293. You might want to verify the exact coordinates of the valid interactive elements.
The agent snapped back, committed to repeating CLICK(5, 32), and solved the level in 5 consecutive rotations.
The nudge functioned as memory recall, preventing the agent from forgetting its own discovery. No new information was provided. The agent was reminded of what it already knew.
Where it did not help
On 10 of 25 games, neither condition solved any levels. These remain genuinely hard puzzles that exceed the agent's current capability regardless of knowledge.
On one game, the system regressed. Thin knowledge coverage around that specific problem type led the oversight layer to associate it with a different class of puzzles, nudging the agent in the wrong direction. The system works best with depth on a task type. With thin coverage, it can confuse patterns. This is the same cold-start dynamic any learning system has.
The 2.6× improvement is computed across all 25 games, regression included.
What this means for production
ARC-AGI-3 is a controlled environment. The properties that make self-learning work there — recurring task types, transferable patterns, and compounding knowledge — exist in every production agent workload.
Coding agents encounter the same classes of bugs across different repos and instances. They hit the same dependency conflicts, framework edge cases, and structural patterns. Customer support bots handle variations of the same issue categories; an agent that has navigated a thousand billing disputes should handle the next one differently. Financial and healthcare agents run into identical regulatory edge cases and data validation failures.
These are not unique problems. These are repeated patterns that are yet to be surfaced.
Recurring patterns exist in every production workload. Improving over time is simply a matter of making prior knowledge available to the next run.
BentoLabs makes your agent's past runs useful to its future ones.
What building this taught us
Knowledge and capability are separate. Same model. Same harness. 2.6× improvement with no model change, no prompt enhancements, and no architectural modification. The agent was always capable of solving those games. What it lacked was knowledge of how.
A mediocre manager who constantly interrupts an exceptional engineer will make them worse. Early iterations of our oversight layer delivered 15 nudges per game with labels like DOOM LOOP and CRITICAL FAILURE IMMINENT. The agent ignored all of them. After calibrating the number of nudges per game, grounded in specific knowledge base entries, agents followed 90% of interventions.
Single-run performance and long-run improvement are different problems. Prompt engineering and model upgrades make the agent better right now. Self-learning makes it better over time. Both matter. Most teams are only solving one.
A capable agent without accumulated knowledge will underperform a less capable agent that has it. The benchmark showed this cleanly. The best model available still leaves significant performance on the table without knowledge.
The feedback loop between runs is the missing layer. Observability tools tell you what happened. A self-learning system makes what happened useful for what comes next. Most production stacks have the first. Almost none have the second.
The cost of not having this compounds. 34% cheaper per successful outcome. Every run that does not carry knowledge forward costs more than it should.
We are building the self-learning layer for production AI agents. If you are running agents at scale and want them to improve with every run, we would like to talk.
Also happy to compare notes if you are working through agent reliability. We have spent a lot of time in this space and enjoy the conversation regardless.
Kaushik ASP & Abhinav Soni
BentoLabs AI (YC P26)
Disclaimer. This is an internal benchmark study, not a competition submission. Our setup uses external knowledge injection and runtime oversight, which falls outside ARC Prize's requirements. The competition mandates open-source code under a permissive license, prohibits internet access during evaluation, and calls for minimal prompts with no client-side harnesses or hand-crafted tools. We use ARC-AGI-3 as a controlled environment to measure the impact of self-learning, not to compete on the leaderboard.