Production AI agents need research infrastructure, not iteration
How we think about closing the loop on agents that get worse over time.
Every production AI agent gets worse before it gets better. The drift is invisible until it isn't. Prompts that worked in week one stop working in week eight. A model upgrade silently changes how the agent handles a category of cases. The engineers who built it rarely know why.
The default response, increasingly, is to point a frontier model at the problem — Opus with extended thinking on the failures, Claude Code on a loop, an LLM-as-judge over the trace history. That works for a single bad run. It does not work for an agent in production. Production isn't a bad run. It's a time-varying distribution.
This post is about what it takes to improve one of those.
Production isn't a bad run
A production AI agent looks deceptively like a piece of software. It has inputs, outputs, a deployment surface. The resemblance ends there.
Its inputs shift continuously — new users, new seasonal patterns. Its dependencies shift — tool APIs change error codes, retrieval indexes get updated, upstream services degrade in ways that don't show up as outages. Its substrate shifts — the model underneath gets a quarterly upgrade and silently changes how it handles edge cases that nobody thought to test.
The agent's outputs change in response to all of this. Often silently. Often in ways no one notices until a customer complaint surfaces a failure that, when investigated, turns out to have been happening for weeks.
This is the structural property that breaks naïve improvement strategies: a production agent is a distribution that varies with time, not a code path that produces a deterministic result. You cannot improve it by debugging a snapshot. You can only improve it by modelling the distribution, attributing changes to their causes, and testing every intervention against the full traffic history.
That requires infrastructure.
Why iterating with a frontier model isn't enough
A fair question we get on every call: “Couldn't we just run Claude Code with extended thinking against our skills, on a loop?”
Frontier models with extended thinking are excellent for the point-in-time parts of agent work — drafting a skill, critiquing a prompt, reading a single trace. We use them throughout our system for exactly those tasks.
What they cannot do is the work between sessions. Improving a time-varying distribution requires capabilities that exist beyond a single session: population measurement across millions of trajectories, attribution of behaviour change to its source, regression checks against the full traffic history, an institutional memory that survives sessions and model upgrades, and an audit trail sufficient for regulated review.
Those capabilities are not prompts. They are infrastructure.
The relationship is the same as psql to production database observability, or git to a CI/CD pipeline. The interactive tool is correct for what it does; the infrastructure is what makes it safe at scale. One runs inside the other.
This is the part of the discussion most teams haven't had yet.
The research loop
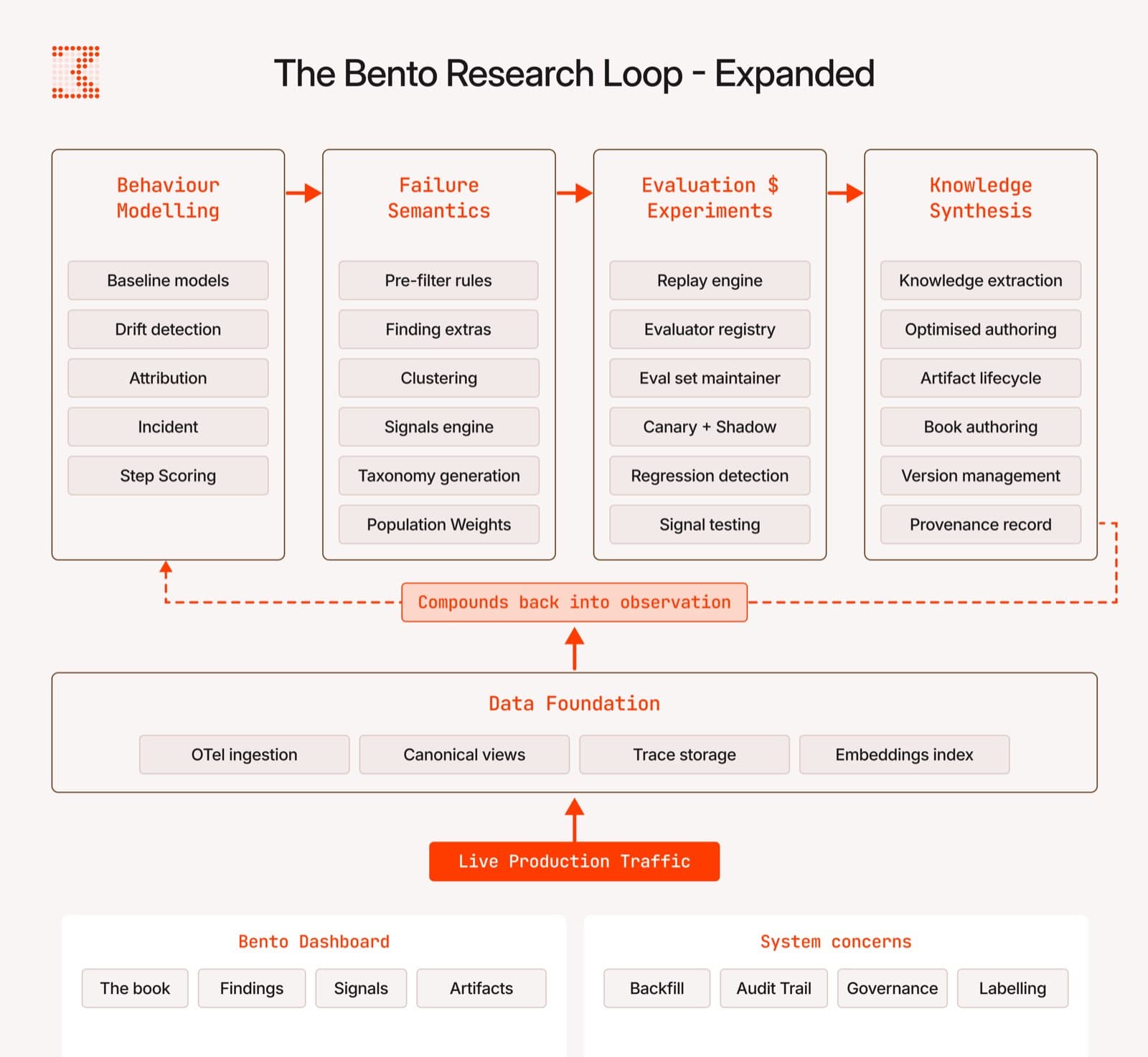
If improving a production agent is a research problem, it should be organised the way research is organised. Our system runs four disciplines as a closed loop, with the output of each feeding the next, continuously, against live traffic.
Behaviour modelling. We treat every agent run as structured behavioural data — a multi-dimensional time series with measurable properties (tool usage, argument distributions, success rate, output structure, latency, step count). We model the rolling baseline for each dimension, detect when current behaviour diverges from historical norms, and attribute the divergence to its source: a prompt edit, a tool change, a model release, a user-cohort shift. Detection is the table-stakes claim every observability tool now makes. Attribution is the work that turns an alert into an actionable cause.
Failure semantics. Raw traces are not actionable. We extract structured semantic understanding from every trajectory — what failed, why, in what context, against what expectation — cluster the results into named classes, weight each class by population frequency, and surface a measurable taxonomy of how the agent fails. The output is not a list of broken examples. It is a ranked, statistical map of failure modes.
Experimentation infrastructure. Hypotheses become validated changes through historical replay across the agent's full traffic record, evaluation suites that gate every release, canary deployment with shadow comparison against ground truth, statistical-significance tests before promotion, and regression checks that ensure no previously-passing case silently fails. Every change carries provenance. Every change carries proof.
Knowledge synthesis. Validated learnings do not stay implicit. They are converted into named, reusable artifacts — skills, sub-agents, tool wrappers, system-prompt fragments — each with a versioned lifecycle. The artifact catalogue is the compounding output of the loop: every validated learning becomes a persistent capability that survives model upgrades, team turnover, and product reorganisation. We make the agent learn with each run, so the past failures and successes improve the future ones.
The loop closes when the artifacts produced by knowledge synthesis return to the agent, and the agent's new behaviour becomes new data for the next cycle of modelling.
The primitives, named
Every system needs a vocabulary its users can reason in. Ours is:
The Book: A plain-language record of every validated learning the agent has produced, ensuring any new engineer or model can be onboarded by reading. The Book is what makes “methodology compounds” a verifiable claim, and what an auditor will eventually ask to see.
Artifacts: Versioned, gated, reversible improvements with explicit lifecycle states (candidate → validated → promoted → deprecated).
Optimisations: Improved skills, tools, sub-agents, and system prompts. The shipped form of an artifact, deployed back into the running agent.
Evaluations: The engine for running evals at scale, against an updated eval set that grows with the agent, not the stale benchmark from three months ago.
Signals & Findings: Signals are measurable failure classes with plain-language definition, statistically tracked rates and trending histograms, while Findings represent the structured semantic labels extracted from individual trajectories.
Drift & Incidents: Drift tracks multi-dimensional behavioural divergence from rolling baseline, while Incidents manage the fan-in of that drift with severity rollup and full lineage to the source.
Backfill: Retroactive analysis that re-scans historical traffic against new hypotheses to recover signal that real-time processes might have missed.
These are our terms-of-art. They are the substrate every higher-order capability is built on. They are also the reason a customer's third conversation with us sounds different from their first. The vocabulary changes how the team thinks about its own agent.
Models change. Methodology compounds.
Frontier models release every quarter. Each release moves the floor. None of them, on its own, solves the problem of improving an agent in your domain, against your users, with your tools.
The agent's accumulated learnings are what should outlast any specific model. When the next frontier model lands, the right question is not “does our agent still work?” but “how much of our methodology — our Book, our artifacts, our evaluators — transferred without re-derivation?” That is the property that compounds.
We saw this empirically when we validated the self-learning layer on ARC-AGI-3: same agent, same tools, same budget, 2.6× the score — because the agent had a place for knowledge to live between runs. Production agents need the same property, with much higher stakes, on much longer timelines.
This is not a feature claim. It is the structural reason production AI agents need research infrastructure rather than iteration. Iteration improves a snapshot. Infrastructure improves the agent.
What we are building
Bento is not a dashboard, an evaluator, or a prompt-tuning surface. It is the research infrastructure that turns an agent's own production traffic into a continuous source of validated, compounding improvement. The substrate it operates on is whatever frontier model the team is currently running. The discipline is what makes those models compound.
You can run a frontier model in a weekend. You cannot, in a quarter, build the research infrastructure that turns its outputs into a measurable, regression-gated, compounding improvement program.
That is the work we do.
If you are running an AI agent in production and want to talk about what this looks like for your specific domain, let's set up a call.