Why your AI agent stops following instructions mid-run

In production-grade AI systems, a specific failure pattern appears as trajectories scale. An agent follows its system prompt precisely at the start of a run. By token 50,000, it is quietly ignoring parts of it.
Most teams diagnose this as a model capability problem and spend weeks adding more instructions. That often makes it worse. The issue is not what is in the prompt. It is where.
The mechanical reality: the attention U-curve
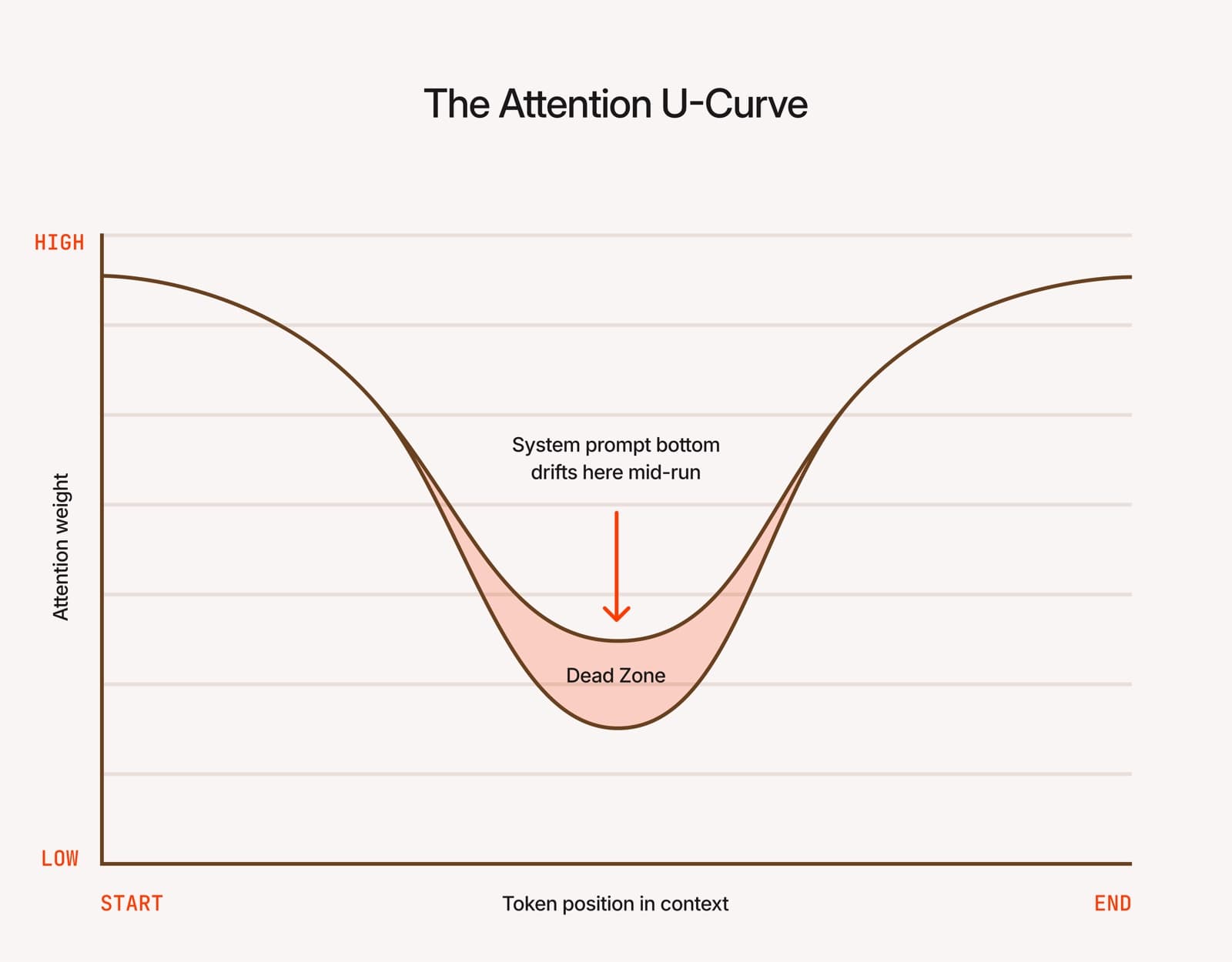
LLMs do not attend to all parts of a long context window equally. Research by Liu et al. (2023) documented a U-shaped attention curve:
- High attention at the very beginning.
- High attention at the very end.
- A “dead zone” in the middle where attention weight drops sharply.
For long-running agents, this creates a specific architectural failure. As a run accumulates tool outputs, subagent responses, and reasoning traces, the system prompt remains static while the context grows. Instructions at the bottom of your prompt drift positionally into the center of the context. By token 50,000, the model has simply stopped attending to them.
The fix: structure your prompt by where, not just what
The standard approach is to order system prompts by human-readable importance. However, importance and timing are distinct engineering requirements. Every instruction must be categorised by its persistence requirement:
| Instruction type | Optimised position | Engineering logic |
|---|---|---|
| High persistence: compliance, safety, identity | Top (token 1) | Token 1 never drifts. It retains high attention for the full duration of any trajectory. |
| High immediacy: task framing, orientation | Bottom | Sits adjacent to the first user message. Fading later is acceptable once the agent is oriented. |
Validating the “zero-code” fix
Reordering an existing system prompt according to this framework produces measurable improvements in long-run agent behavior without changing a single word of content.
The test:
- Move non-negotiable constraints to the absolute top.
- Move task setup and initial framing to the absolute bottom.
- Re-run across long context windows and measure the reduction in “instruction drift.”
For organizations running agents across payments, compliance, or customer operations, this is a reliability risk. An agent silently operating outside its boundaries produces no visible error. It produces an audit failure or a policy breach traceable only after the fact.
The teams that solve this early share one capability: they observe agent behaviour across the full trajectory, not just the initial output.
What your monitoring misses at 50,000 tokens
Most tools stop one layer too early. Existing LLM observability was built around the unit of a single call. Evaluator frameworks score outputs against a rubric. None of that surfaces attention drift.
Here is why. A single call at token 35,000 looks fine in isolation — the model responded, the JSON parsed, no exception was raised. The failure is structural, not per-call: the instruction the model was supposed to apply is now living in the dead zone of its own context. You can only see it by comparing a trajectory to how the agent used to behave three hundred runs ago. That is the layer we work on. Observability for the whole trajectory, not the first request.
Most LLM monitoring was shaped by the chatbot wave: one prompt, one response, one eval set, one regression test. When agents run for hours, spawn subagents, accumulate tens of thousands of tokens, and touch payments, compliance, and customer data, the failure modes do not look like the ones the tooling was designed for. Attention drift is the canonical example. By the time it matters, you are forty thousand tokens into a run that no trace viewer was built to read end-to-end, and no eval in your CI ever reached that part of the context window.
The gap worth closing
The industry has reliability tooling for LLM apps. It does not yet have reliability tooling for long-running agents operating under real constraints. That problem deserves better infrastructure than it currently has.
Half the things you discover in production are already in a paper you have not read. The other half are not in any paper at all because not everyone in a research setting has seen what you are seeing at scale.
~ Abhinav Soni, BentoLabs
If you are building agents that run in production and you have started noticing things the papers do not explain, you are not imagining it. That territory is real, and it is worth mapping carefully. So if you are starting to see things that do not fit the standard playbook, we would like to talk — let's solve it together.