TB2: The benchmark where a score improvement actually means something in production

Compile SQLite from source with full gcov instrumentation. Build the Linux kernel with QEMU. Fix the OCaml garbage collector after a failed optimisation, a task that takes a domain expert close to a full day.
These are 3 of the 89 tasks in Terminal-Bench 2.0. The same work your agent gets asked to do in production, in a real terminal, with no hints and no partial credit. The score it gets here is the score that actually tells you something.
The leaderboard everyone wants to crack
Terminal-Bench is the benchmark for testing long-running AI agents in real terminal environments. It has been adopted by frontier labs including Anthropic, OpenAI, and Google DeepMind, and has helped drive progress in AI agents by defining what those labs measure and optimise for.
That adoption actually came from engineers looking at the task list and recognising that these were the actual problems their agents were being asked to solve in production.
Substantial manual and LM-assisted verification went into the creation of each task in Terminal-Bench 2.0, with every task carrying a human-written reference solution and a verifier that checks behavioural output rather than anything the agent says about itself. When you look at the leaderboard through that lens, the scores stop feeling like benchmark numbers and start feeling like production reliability numbers, because that is precisely what they are.
Why the previous version did not make sense
Passing TB1 used to mean your model could navigate a filesystem, chain a few commands together, not fall apart mid-task. But once models started crossing the 50% threshold consistently, the benchmark stopped separating good agents from great ones. It was measuring advanced text generation with shell syntax at that point, not agentic autonomy. That is a very different thing. While it proved the model wouldn't instantly crash or panic mid-task, it lacked long-horizon planning. A model could pass TB1 just by being an excellent text predictor that understood terminal commands. It did not have to dynamically recover from unexpected system errors, handle complex multi-step dependencies, or reason through ambiguous edge cases.

So why Terminal-Bench 2.0? We always knew that as model capabilities increased, we'd need to keep Terminal-Bench up to date with frontier capabilities. Terminal-Bench 2.0 consists of 89 hard tasks to test these capabilities. We aim to push the frontier with an increased emphasis on task quality. Each task received several hours of human and LM-assisted verification to ensure that tasks are (1) solvable, (2) realistic, and (3) well-specified. We'll share more on how we did this in our upcoming preprint.
~ By the creators.
TB2 is an industry-standard, open-source benchmark designed to evaluate how autonomously AI agents can operate within command-line interfaces (CLI) and realistic Linux environments.
It was developed out of the core philosophy that if you want to test whether an AI agent can execute complex, real-world engineering tasks (like compiling software or managing data processing pipelines), you should sandbox it in a terminal.
What TB2 actually puts your agent through
TB2 contains 89 high-quality tasks across software engineering, machine learning, security, data science, and more. The agent gets a task description, a terminal, a filesystem, and a set of tools. No human to course-correct midway through. It has to get from the starting state to a verified correct end state entirely on its own.
A few examples pulled directly from the benchmark:
- Configure a Git server with a post-receive hook that deploys content to a webserver
- Compile SQLite from its amalgamation source with full gcov instrumentation and pass the test harness that validates coverage output
- Build the Linux kernel from source with QEMU
- Crack an encrypted 7z archive with a hash
- And train a fastText model on Yelp data
| Domain | Example task |
|---|---|
| DevOps | Configure a Git server with a post-receive deployment hook |
| Systems | Compile SQLite with gcov instrumentation |
| Infrastructure | Build the Linux kernel from source with QEMU |
| Security | Crack an encrypted 7z archive |
| Machine learning | Train a fastText model on Yelp data |
| Formal verification | Fix the OCaml garbage collector |
These are not toy tasks invented to trip up a model. Each task undergoes several hours of human and LM-assisted validation to ensure it is solvable, realistic, and well-specified.
Understanding what it takes to move TB2 is, more than with any other benchmark, the same as understanding what it takes to build more reliable production agents.
How TB2 actually works and what makes it hard to game
Each task in TB2 is built around an instruction, a pre-configured Docker image, a test suite, a reference solution, and a time limit. It works interactively issuing shell commands, editing files, running builds, whatever approach it takes. When time is up, the tests run against the final container state. They do not check what commands the agent ran or what it printed, only whether the end state is correct. Pass all tests: score 1. Miss one: score 0.
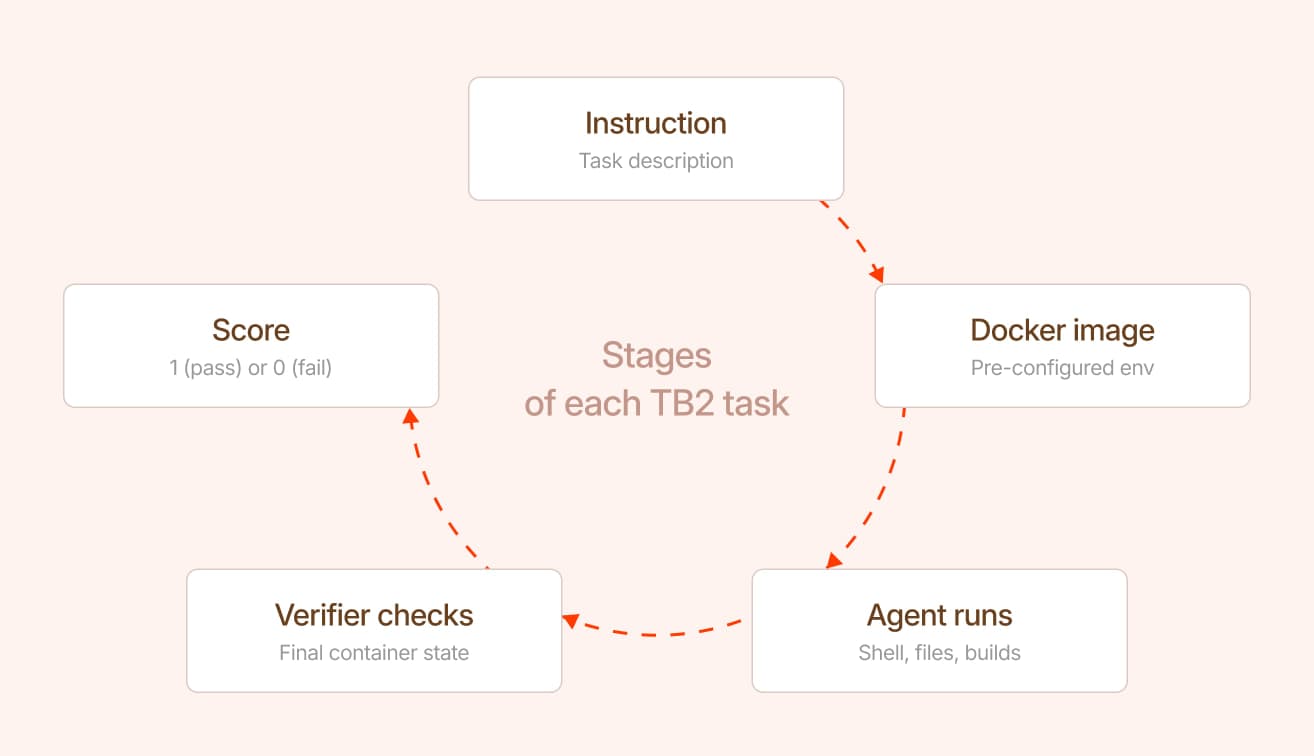
What makes it hard to game
- 229 tasks were submitted. 89 made it. Every rejected task either wasn't hard enough, wasn't realistic enough, or didn't hold up under scrutiny.
- Before any task enters the benchmark, a dedicated exploit agent is run against it specifically to find shortcuts. If it cheats its way to a passing score, the task goes back for fixes.
- A no-op dummy agent that does nothing must fail every task. If it passes, the task is rejected outright.
- Integrity is enforced at the environment level. If a task involves a git repo at a specific commit, all future commits are stripped from the history. The agent cannot look ahead.
- Each task averaged three hours of combined human reviewer attention not counting the time it took to build it.
- The hardest task in the set, fixing the OCaml garbage collector after a failed optimization, takes a domain expert close to a full day. A junior engineer: 240 hours.
What happens when you add a recursive learning layer?
We ran a dedicated engineering trial against the TB2 official leaderboard baseline.
We kept the core variables completely static: the exact same model, the same evaluation harness, and the same budget. Of the 89 tasks, 34 went into training, 38 into testing, and 17 were dropped. The one thing we introduced was a recursive learning layer.
Instead of treating each run as a standalone attempt that discards everything it learned, the recursive learning layer wraps the agent's execution loop. After each run it distills what happened into structured knowledge entries, each carrying a measured estimate of whether acting on it actually helps. Before the next run it selects what is relevant, injects it into the agent's opening context, and enforces a verification protocol that forces the agent to check its own work before declaring done.
When you give an agent the structural runtime framework to analyze its own execution failures and adapt recursively, the baseline ceiling cracks wide open.
Want to dive deeper into the exact architecture of this recursive learning layer?