+10.2 pp pass@1 on Terminal-Bench 2.0 with a recursive learning layer: same agent, same model, same budget
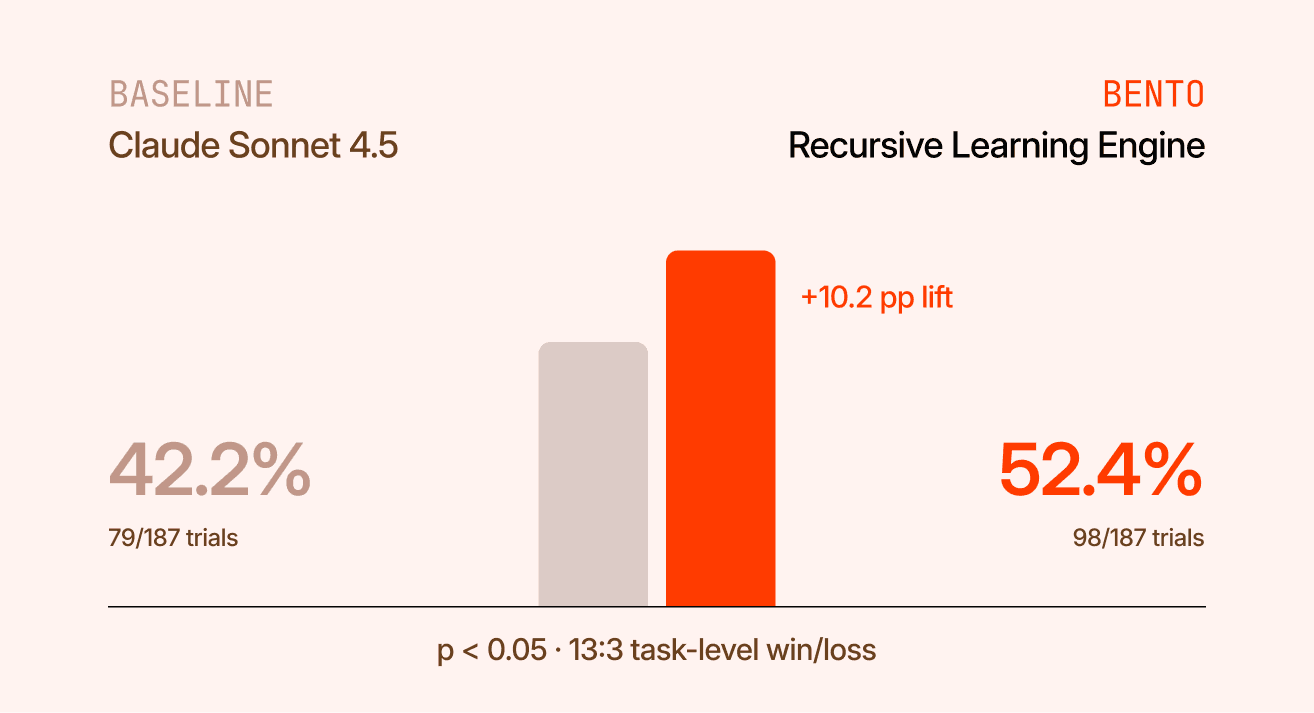
We ran a controlled experiment against the official Terminal-Bench 2.0 leaderboard.
The published Claude Sonnet 4.5 baseline scores 42.2% pass@1. With our self-learning engine wrapping the same agent, same model, same harness, same hardware, same budget, pass@1 rose to 52.4%.
A +10.2 percentage-point lift, significant at p < 0.05, with a 13:3 task-level win/loss ratio.
The model did not change it just the agent stopped re-deriving the same dead ends from scratch on every run, and stopped declaring victory before verifying its own work. This post is a technical walkthrough of how the engine produces that lift, with the actual measured artifacts including book entries, lift numbers, and per-trial solutions.
The result
The comparison is matched-N: same 38 tasks, same trial counts per task as the official leaderboard, same verifier code.
| Condition | Passes / Trials | Pass@1 (± SE) | 95% Wilson CI |
|---|---|---|---|
| Baseline (official Sonnet 4.5, TB2 leaderboard) | 79 / 187 | 42.2% ± 3.6% | [35.4%, 49.4%] |
| Bento Recursive Learning Engine | 98 / 187 | 52.4% ± 3.7% | [45.3%, 59.4%] |
The ± is one standard error of the binomial proportion, √(p(1−p)/n), the same convention the TB2 leaderboard reports. The +10.2 pp delta is significant under a two-proportion test at p < 0.05. The engine adds 19 net trial passes on the same 187-trial base. The single largest per-task move: regex-log, 1/5 → 5/5 (+80 pp), dissected later in this post.
This is a frozen-book evaluation, meaning the engine's knowledge base does not update during scoring. That's deliberate, and we'll explain why it's the honest baseline.
How production AI agents improve today
When an agent fails a task, the levers available to most teams are:
- Wait for a stronger base model.
- Iterate on the system prompt.
- Add a new tool/subagent, a retry budget, or a scratchpad.
- Fine-tune on the failure distribution.
Notice the pattern? All four operate outside the agent's execution loop. The agent itself carries nothing forward. Run N+1 starts in exactly the same state as run N, re-spending tokens to rediscover what run N already learned and threw away. The improvement, if any, lives in a human's head or in a new checkpoint, never in the agent.
For a benchmark like Terminal-Bench 2.0, that's expensive. Tasks run up to a 60-minute wall. An agent that burns 40 minutes down a dead end it has already explored on a prior trial is paying full freight for zero information gain.
Agents that learn from experience
A learning agent maintains an explicit, structured memory of what it has attempted, what the outcome was, and a measured estimate of whether acting on each memory actually helps. Before a run it selects relevant memories and conditions on them. After a run it writes new memories and updates the statistics on the ones it used.
The naive version of this is RAG over past transcripts. It doesn't work, for three reasons that took us a while to fully internalize:
- Transcripts aren't lessons. A 40-step trajectory contains maybe one transferable insight. Retrieving the raw trajectory buries that insight in noise the next agent has to re-read and re-interpret.
- Recall is the easy half; suppression is the hard half. Surfacing a confidently-stated but wrong memory is worse than surfacing nothing because it actively steers the agent into a mistake it wouldn't have made on its own.
- Relevance is not correctness. A memory can be topically on-point and still hurt. You only find out by measuring outcomes, not by measuring embedding similarity.
The engine is built around those three constraints.
How the recursive learning engine works

Three phases wrap any agent execution. We'll describe what each phase produces in terms of observable artifacts, without the internal machinery.
Knowledge is not stored raw, it is typed and measured typed
After each run, the engine distills the trajectory into structured entries. An entry is a typed claim with a trigger condition and a running empirical record. Here is a real one from the git-plumbing book, exactly as it sits in the knowledge base after scoring (this is shipped verbatim in our published trace package):
two-permission-planes — status: validated
format: mechanic_model
confidence: 0.95
measured lift: +0.50
use / success / fail: 5 / 5 / 0
trigger: When a Git push succeeds but deployed files do not
appear in the served directory.
content: A Git-over-SSH static deployment has two independent
permission planes: SSH/repository access controls
clone/push; web-root filesystem permissions control
whether the hook can deploy. The hook runs as the
SSH/repository user, so the deploy dir must be
writable by that user.The fields that matter:
trigger— a precondition the engine matches against the current task, not a topic tag. An entry only competes for surfacing when its trigger plausibly fires.measured lift— the empirically estimated change in success rate when this entry is surfaced versus not. A value of+0.50means trials that saw this entry resolved at a rate 0.5 higher than the counterfactual. This is the number that governs whether the entry survives.use / success / fail— the sample backing the lift estimate. Lift on 1 use is a guess; lift on 17 uses is a measurement.status—validated(positive lift, sufficient N),candidate(promising, low N), ordemoted(negative lift, retired from active surfacing).
This is the difference between “memory” and a learning system: every entry carries its own evidence, and the evidence decides its fate.
Retrieval is selective to the point of usually saying nothing
Before a run, a lightweight selector reads the task description and the relevant book's table of contents and proposes a small set of entries. Across the 38 scored tasks, the engine had roughly 1,469 entries available in the in-scope cluster books. It surfaced 49 unique entries total, a 3.3% surfacing rate. For 2 of the 38 tasks it surfaced nothing at all, because nothing cleared the relevance-and-confidence bar.
That abstention is a feature. A system that always returns its top-k is a system that injects noise on every task where it has no real knowledge. Calibrated abstention, returning empty rather than forcing a marginal match, is what lets the engine help on the tasks it knows and stay neutral on the tasks it does not.
The structural layer is content-independent
Alongside any surfaced entries, the engine injects a verification protocol: before the agent may declare a task complete, it must enumerate every explicit requirement in the instruction, state how each was satisfied, and run a concrete check (ls the artifact, cat a sample, run the command the instruction names). This is content-free, and carries no task-specific knowledge.
The book self-curates
Every surfacing updates the used entries' statistics. When an entry's measured lift goes negative over enough uses, it is demoted and stops being surfaced, kept in the book for audit, flagged as historical. The book that starts run N+1 is strictly better-calibrated than the one that started run N, with no human in the loop.
The agent is unmodified. The model is unmodified. The harness is unmodified. The engine is visible to the agent only as text in its opening context.
The experiment
Why Terminal-Bench 2.0
Terminal-Bench 2.0 is the one of the most demanding public benchmark for long running agentic work: 89 tasks across 12 clusters, graded by hidden verifier suites, with a human-expert time budget of 45–180 minutes per task. The tasks are real systems work including fix the OCaml garbage collector, build SQLite from amalgamation source with full gcov instrumentation, stand up a Git-over-SSH deployment with HTTPS and a post-receive hook publishing two branches to separate endpoints. Claude Sonnet lands in the 30–45% pass@1 band. The benchmark forbids the usual escape hatches: no timeout multipliers, no resource overrides, no network access to the benchmark site during a run.
It's a good stress test for a learning layer precisely because the tasks are long-horizon and verifier-graded: there's no partial credit, and the failure modes are subtle (a missing file, a wrong octet range, a service that binds the wrong port).
Setup
- Scored tasks: 38 of the 89 TB2 tasks, this is the subset where we had a matched-trial-count baseline from the official leaderboard. The remainder were out-of-cluster for us or used as warmup material (and excluded from scoring).
- Trials: 5 per task = 187 in the matched-N comparison (3 tasks have 4 baseline trials on the board).
- Model: Claude Sonnet 4.5 (
claude-sonnet-4-5-20250929@anthropic) in both arms. - Hardware: Mac M4 Air with Rosetta (same as the published baseline).
- Validation:
timeout_multiplier=1.0, no resource overrides, Docker-sandboxed, no reward hacking. All TB2 leaderboard validation rules satisfied.
The harness
We used the standard Terminal-Bench 2.0 harness: same runner, same verifier, same scoring code. The only delta between arms is the agent's opening context: the baseline gets the default terminus prompt; the engine arm gets that prompt prefixed with the verification protocol plus whatever entries the selector surfaced for that task. Everything downstream including the batched-keystroke execution loop, the terminal-state feedback, the verifier is identical.
Results
Full 38-task evaluation
| Cluster | Tasks | Baseline | Engine | Δ |
|---|---|---|---|---|
| puzzles-formal | 3 | 5/15 (33.3%) | 10/15 (66.7%) | +33.3 pp |
| git-plumbing | 3 | 8/15 (53.3%) | 12/15 (80.0%) | +26.7 pp |
| ml-train-inference | 9 | 12/45 (26.7%) | 17/45 (37.8%) | +11.1 pp |
| build-systems | 11 | 22/53 (41.5%) | 26/53 (49.1%) | +7.5 pp |
| data-etl | 3 | 8/15 (53.3%) | 9/15 (60.0%) | +6.7 pp |
| system-admin-services | 6 | 24/29 (82.8%) | 24/29 (82.8%) | 0 |
| code-modernization | 2 | 0/10 (0%) | 0/10 (0%) | 0 |
| debugging-broken | 1 | 0/5 (0%) | 0/5 (0%) | 0 |
| TOTAL | 38 | 79/187 (42.2%) | 98/187 (52.4%) | +10.2 pp |
Read this distribution carefully, because the shape is informative:
- The lift concentrates where the book had compounded, validated content. puzzles-formal and git-plumbing show the largest deltas because these clusters had warmup-derived entries with positive measured lift (like
two-permission-planes, +0.50). - system-admin-services is at the joint ceiling. 82.8% in both arms. The engine can't lift trials the model already passes, and the remaining failures there are beyond what Sonnet 4.5 can do at all.
- Two clusters stay at 0%.code-modernization and debugging-broken are flat zeros in both arms, tasks that exceed the model's reach regardless of context. The engine correctly does not manufacture phantom passes.
A learning layer that lifted everything uniformly would be suspicious. A layer that lifts where it has knowledge, holds steady at the ceiling, and stays at zero where the model is fundamentally stuck, that's the signature of a system actually conditioning on what it knows.
Disclaimer. This is an internal benchmark study, not a competition submission. We use Terminal-Bench 2.0 as a controlled environment to measure the impact of our recursive learning engine, not to compete on the leaderboard.
Decomposing the lift: structural vs content
The most important technical question is why the lift happens, because that determines whether it generalizes. We can decompose it using two tasks as natural experiments that isolate the content-free structural component.
prove-plus-comm (Coq proof completion). The selector surfaced zero entries, the book had no formal-proof content. The agent ran on the verification protocol alone. Result: 4/5 → 5/5. Pure structural lift, zero content.
regex-log (the +80 pp task). The selector surfaced two entries, both chess-related (the puzzles-formal book was built from chess and corewars warmup tasks). One was already demoted. Neither has anything to do with regular expressions. Result: 1/5 → 5/5. The content was irrelevant and the agent ignored it; the lift came from structure alone.
These two tasks tell us the dominant lever in this experiment is the verification protocol, specifically forcing the agent to test before it declares done rather than the retrieved knowledge. The content lever is real and measurable (it's why git-plumbing moved +26.7 pp on the back of validated entries), but it's the second-order term. The first-order term is structural, which is exactly why it transfers across task types as different as Coq proofs and regex construction.
This is a falsifiable claim: if you strip the book entirely and keep only the verification protocol, the model in this decomposition predicts you'd retain most of the lift on structurally-fixable tasks and lose the cluster-specific content gains. We think that's the right mental model for where this kind of engine helps.
regex-log: five correct solutions, none memorized
regex-log asks for a single regular expression that matches the last YYYY-MM-DD date on log lines that also contain a valid IPv4 address, with calendar-aware date validation, octet-range validation (0–255, no leading zeros), negative anchoring so Text2023-01-01 and 192.168.1.1abcdon't match, and a “last date only” constraint enforced by negative lookahead. The verifier throws adversarial cases at it: 2023-13-01 (bad month), 192.168.1.256 (bad octet), multi-date lines, alphanumeric-adjacent near-matches.
The baseline passes 1/5. The engine passes 5/5. The decisive evidence that this is genuine problem-solving and not a cached answer: the five passing trials produced five structurally different regexes.
trial_1 (403 chars) positive-lookahead IP assertion, separate capture for last date trial_2 (394 chars) (?<!\w) / (?!\w) anchoring + month-length-aware day validation trial_3 (314 chars) \b word boundaries, compact octet alternation trial_4 (304 chars) anchored, full calendar validation (30/31-day months, Feb) trial_5 (234 chars) minimal \d-class form with lookaround anchoring
Five independent derivations, ranging 234–449 characters, using different anchoring strategies and different depths of calendar validation. A memorized answer reproduces one string five times. This is the model genuinely solving the task five times and succeeding each time because the verification protocol made it write a Python test, run its own regex against the adversarial cases, watch it fail, and iterate before declaring done. The baseline writes a plausible regex and stops. Same model; the difference is the stopping rule.
Where it did not help, and what the engine did about it
Three tasks regressed ≥ 20 pp with the engine on. This is the honest counterweight, and one of them is the most technically interesting result in the run.
compile-compcert: 4/5 → 2/5. The selector surfaced a build-systems entry about missing Fortran .modfiles. compcert is OCaml, not Fortran. The entry was topically adjacent (build failures, missing-module errors) but causally wrong, and it steered the agent toward the wrong diagnostic path. Here's the entry, in its current state:
"Missing Fortran module file means dependency/order bug" — status: demoted measured lift: -0.26 use / success / fail: 17 / 4 / 0 deprecation reason: Negative lift (-0.265) after 17 uses
The engine measured this entry hurting across 17 surfacings, computed a negative lift of −0.26, and demoted it. It is no longer surfaced. The regression on compile-compcert is precisely the signal the demote loop is built to catch, and it caught it. The run that produced this scoreboard was the run that taught the engine this entry was bad. The next run starts without it.
cobol-modernization: 5/5 → 4/5. One trial took a longer path triggered by a staging-and-package entry and hit the time wall.
password-recovery: 2/4 → 1/4 — a single trial on a 4-trial denominator, inside sampling noise.
13 wins, 3 losses, and the losses are self-documenting: each is a marked entry with a measured negative lift that the engine has already retired. The system's error correction is observable in the published artifacts.
Statistical methodology
A few choices that make this a measurement rather than a demo:
- Matched-N. We compare against the exact trial counts the official leaderboard ran. Where the baseline had 4 trials, we truncate to 4. No denominator games.
- Binomial SE and Wilson intervals. We report
√(p(1−p)/n)for the point estimate and Wilson score intervals for the 95% CI, because at n=187 and p near 0.5 the normal approximation is fine for SE but Wilson is better-behaved for the interval. - Significance on the delta.+10.2 pp at p < 0.05 under a two-proportion test. The CIs overlap slightly at their tails, which is expected at this N; the paired-task structure (same tasks, same trials) makes the two-proportion test conservative here.
- Frozen book.The knowledge base does not update mid-scoring. If we let it learn across trials, regex-log trial 1's success would inform trials 2–5 and inflate the number. We froze it so the comparison is against a baseline that also has no cross-trial memory. The cross-trial-learning configuration is a separate experiment with its own scoreboard.
The full trace package including every trial directory, every agent recording (.cast), every verifier verdict, and the exact per-task injected context, is published so any of these numbers can be recomputed independently with the stock TB2 harness.
What this means for production
The transferable win is a stopping rule.The dominant lever here, verifying before completing is content-independent and showed up across Coq proofs, regex construction, and build tasks alike. If your agent has a “declares success too early” failure mode (most do), this is the cheapest high-leverage fix available, and it requires no model change.
Calibrated abstention is what makes retrieved knowledge safe. The engine surfaced knowledge on 36 of 38 tasks and correctly nothing on 2. A retrieval layer that can't say “I have nothing useful here” will, at production scale, inject a wrong-but-confident memory often enough to erase its own gains. The 3.3% surfacing rate is not the engine being weak; it's the engine being calibrated.
Self-correction has to be measured, not assumed. compile-compcert regressed because a topically-relevant entry was causally wrong. The only reason that's acceptable is that the engine measured the regression, attributed it to a specific entry, and retired that entry automatically. A learning system without a demote loop doesn't get better over time; it accumulates confident bad advice and slowly degrades.
Cost shape, not just score. Trials that solved, solved faster; trials that failed, failed earlier, because the verification protocol surfaces unmet requirements before the agent spends its full budget hand-rolling a wrong solution. For production volumes, reliability-per-token moves alongside the headline pass@1.
What building this taught us
A few things we learned the hard way:
Selection is harder than extraction. Producing candidate lessons from a trajectory is the easy part. Deciding which two to surface, and when to surface none, is where the engineering went. Two relevant entries beat twenty marginal ones, every single time.
Negative lift is the most valuable signal in the system. Our first build had no demote loop; entries only accumulated. Performance rose, plateaued, then decayed as confident-but-wrong entries started outvoting the good ones. Measuring lift and retiring on negative evidence is what converts a one-time prompt-engineering win into a system that holds and compounds gains.
Honest empty answers beat plausible wrong ones. Two scored tasks surfaced nothing. The engine could have hallucinated a tangential match. Instead it abstained, and one of those tasks (prove-plus-comm) improved anyway on structure alone, while the other (write-compressor) stayed at 0/5 and told us exactly where the book is missing material. Both outcomes are useful.
Frozen-book scoring is the disciplined choice. Cross-trial learning would have produced a bigger headline number and a worse experiment. We measured the static-injection benefit against a memoryless baseline so the +10.2 pp means what it says.
Raw traces - every trial directory, agent recording, and verifier verdict from this experiment.
If you are running agents at scale and want them to improve with every run, we'd love to chat.



